Tsinghua & Kuaishou Breakthrough: SVG Model Boosts AI Training by 6200%
Revolutionary AI Model Shatters Efficiency Barriers
In a landmark collaboration, Tsinghua University and Kuaishou's Ling team have unveiled the SVG (VAE-free latent diffusion model), marking a potential paradigm shift in generative AI technology. Their breakthrough addresses fundamental limitations plaguing current Variational Autoencoder (VAE) systems while delivering unprecedented performance gains.
The Decline of Traditional VAE Models
VAE technology has increasingly struggled with "semantic entanglement" - where modifying one image feature inadvertently alters unrelated characteristics. This phenomenon creates distorted outputs when attempting targeted edits (e.g., changing a cat's color while preserving its expression).
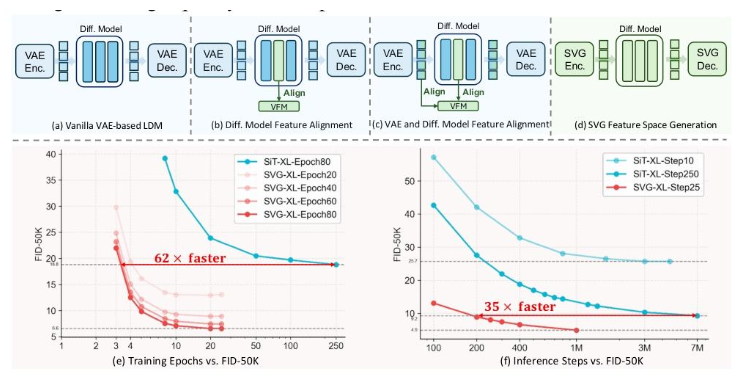
Architectural Innovations Behind SVG
The research team implemented three key technical advancements:
- Semantic Extraction: Employed DINOv3 pre-trained models for precise feature separation through large-scale self-supervised learning
- Detail Preservation: Designed lightweight residual encoders to maintain intricate visual elements without semantic interference
- Feature Fusion: Developed novel distribution alignment mechanisms ensuring harmonious integration of semantic and detail features
The approach fundamentally rethinks latent space construction, eliminating compromises between generation quality and computational efficiency.

Benchmark-Defying Performance
The SVG model demonstrates extraordinary capabilities across multiple metrics:
- Achieved FID score of 6.57 on ImageNet after just 80 training cycles (versus hundreds typically required)
- Requires fewer sampling steps while maintaining superior image clarity
- Features direct applicability to downstream tasks (classification, segmentation) without fine-tuning
- Demonstrates strong generalization across multimodal generation scenarios
The paper reveals particularly impressive comparisons against conventional approaches: | Metric | SVG Improvement | |--------|----------------| | Training Efficiency | +6200% | | Generation Speed | +3500% | | FID Score Advantage | >40% better |
Future Implications & Availability
This technological leap promises transformative applications across:
- Real-time content generation platforms
- Professional creative tools
- Automated visual design systems The research paper detailing these findings is publicly available on arXiv.
Key Points:
- SVG model eliminates VAE's semantic entanglement limitation
- Combines DINOv3 semantic extraction with novel residual encoding
- Delivers order-of-magnitude improvements in speed and efficiency
- Maintains backward compatibility with existing workflows
- Opens new possibilities for real-time generative applications



