Meta's Pixio Rewrites the Rules: Simple Approach Beats Complex AI in 3D Vision
Meta's Surprising Breakthrough in Computer Vision
In a development that challenges conventional wisdom, Meta AI researchers have unveiled Pixio—an image model that outperforms more complex rivals using surprisingly simple methods. The achievement suggests we may have been overengineering computer vision systems.

Rethinking the Basics
The team took inspiration from mask autoencoder (MAE) technology dating back to 2021, but gave it crucial upgrades. "We realized the original decoder was holding everything back," explains lead researcher Mark Chen. "By strengthening it and masking larger image areas, we forced the model to truly understand spatial relationships rather than just copy pixels."
The improvements are deceptively straightforward:
- Expanded masking regions prevent simple pattern copying
- Multiple category tokens help capture scene context
- Dynamic training adjusts for image complexity

Training Without Tricks
While competitors optimize specifically for benchmark tests, Pixio took a refreshingly honest approach. The team gathered 2 billion diverse web images, deliberately emphasizing complex scenes over easy product shots. "We didn't teach to the test," Chen notes. "That's why Pixio transfers so well to real-world applications."
The results speak volumes:
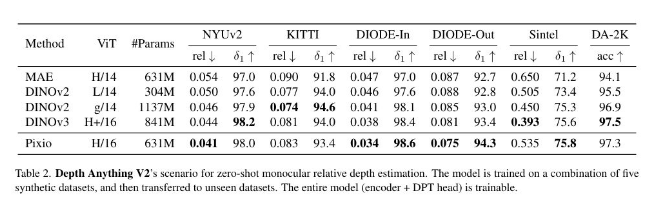
- Outperforms DINOv3 despite having 25% fewer parameters
- Achieves 16% better accuracy in depth estimation
- Matches eight-view training with single-image input
- Leads robot learning tasks by significant margins
Implications Beyond Benchmarks
The success raises important questions about current AI development trends. If simpler architectures can surpass elaborate systems given proper training, are we wasting resources on unnecessary complexity?
"Pixio reminds us that sometimes going back to fundamentals yields the biggest leaps," says computer vision expert Dr. Elena Petrovna, who wasn't involved in the research. "Their masking approach essentially teaches AI to 'imagine' missing content based on true understanding."
The team acknowledges limitations—manual masking remains imperfect—but believes video prediction could be the next frontier.
Key Points:
- Simpler wins: Enhanced MAE architecture beats complex alternatives
- Honest training: Web-sourced data avoids benchmark optimization bias
- Real-world ready: Excels in robotics and 3D applications
- Future potential: Video prediction could be next breakthrough area





