SenseTime's NEO Breaks Multimodal Barriers with Leaner, Faster AI
SenseTime Rewrites the Rules for Multimodal AI
In a move that could reshape how artificial intelligence processes multiple data types, SenseTime has teamed up with Nanyang Technological University's S-Lab to introduce NEO - the industry's first truly native multimodal architecture. This isn't just another incremental improvement; it's a complete reimagining of how AI handles visual and textual information together.

Breaking Free from Patchwork Designs
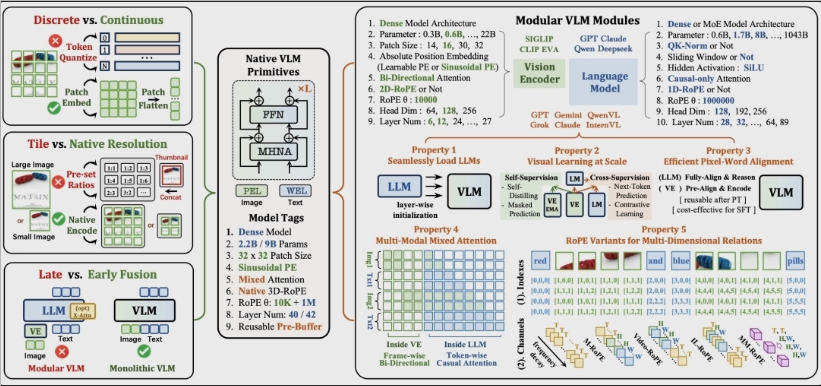
Traditional multimodal systems resemble Rube Goldberg machines - stitching together separate components for vision processing, projection, and language understanding. "We realized this Frankenstein approach was creating unnecessary bottlenecks," explains SenseTime's technical director. NEO throws out this fragmented design entirely.
The breakthrough comes from three radical innovations:
- Native pixel reading eliminates standalone image tokenizers
- 3D rotation position encoding unifies text and visual data in one space
- Hybrid attention computation boosts spatial understanding by 24%
"What surprised us most was the efficiency gains," the director adds. "We're achieving state-of-the-art results with just one-tenth the training data of comparable systems."
Performance That Speaks Volumes
The numbers tell an impressive story. Across the compact 0.6B-8B parameter range (perfect for edge devices), NEO dominates industry benchmarks:
- ImageNet: New accuracy records
- COCO: Enhanced object recognition
- Kinetics-400: Superior video understanding
Perhaps most remarkably, all this happens with sub-80ms latency on mobile hardware - fast enough for real-time applications without draining batteries.
Open Source Momentum Builds
The tech community is already buzzing about SenseTime's decision to release both model weights (2B and 9B versions) and training scripts publicly on GitHub. Early adopters praise the move as accelerating innovation in compact AI systems.
The roadmap looks equally promising:
- Q1 2026: Planned releases for 3D perception
- Mid-year: Video understanding upgrades
The implications are profound. As one industry analyst puts it: "NEO isn't just better technology - it might finally kill off the modular approach that's held back multimodal AI for years."
Key Points:
- 🚀 90% less data: Achieves SOTA performance with dramatically reduced training requirements
- ⚡ Blazing speed: Sub-80ms latency makes edge deployment practical
- 🔓 Open ecosystem: Full weights and scripts available now on GitHub
- 🔮 Future-ready: 3D and video versions coming soon



