Tencent's WeDLM Turbocharges AI Reasoning With Diffusion Model Breakthrough
Tencent's New AI Model Delivers Lightning-Fast Reasoning
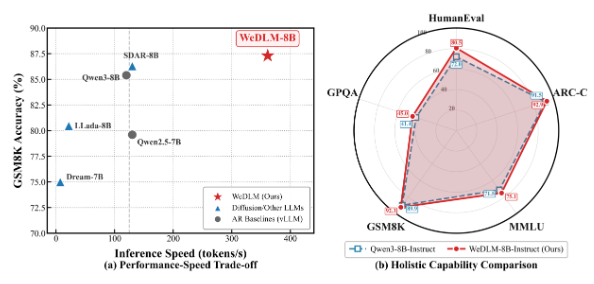
The tech giant's WeChat AI team has cracked open new possibilities in language processing with WeDLM (WeChat Diffusion Language Model). This isn't just another incremental improvement - it represents a fundamental shift in how AI models handle complex reasoning tasks.
Breaking the Speed Barrier
Traditional language models like GPT often hit bottlenecks when processing multiple parallel requests. WeDLM tackles this head-on by combining diffusion models - typically used in image generation - with standard language processing techniques. The secret sauce? An innovative "topological reordering" approach that maintains compatibility with existing KV cache technology.
"What excites us most is seeing these theoretical improvements translate to real-world performance," explains Dr. Li Wei, lead researcher on the project. "In our GSM8K math reasoning tests, WeDLM-8B processed solutions three times faster than comparable autoregressive models."
Quality Meets Velocity
The true test comes when speed doesn't compromise accuracy. Benchmark results tell an encouraging story:
- ARC Challenge: Matched or exceeded traditional model performance
- MMLU: Demonstrated superior comprehension capabilities
- Hellaswag: Showed particularly strong results in contextual understanding
For low-entropy counting tasks, the speed advantage becomes even more dramatic - sometimes exceeding 10x improvements over conventional approaches.
Practical Applications Coming Soon
This breakthrough couldn't come at a better time as demand grows for responsive AI systems:
- Customer Service: Near-instant responses to complex queries
- Coding Assistants: Faster code generation and troubleshooting
- Education Tech: Real-time explanations for math and science problems The team has already made the model available on GitHub, inviting developers to explore its potential.
Key Points:
- ⚡ Blazing Speed: Topological reordering enables processing speeds 3-10x faster than current models
- 🧠 Smart Scaling: Maintains quality while handling complex reasoning tasks efficiently
- 💼 Business Ready: Particularly suited for customer service, coding assistance, and educational applications



