NVIDIA Open-Sources OmniVinci Multimodal AI Model
NVIDIA Breaks New Ground with Efficient Multimodal AI
NVIDIA Research has open-sourced its advanced OmniVinci multimodal understanding model, marking a significant leap in artificial intelligence capabilities. The model demonstrates remarkable efficiency, requiring only 0.2 trillion training tokens compared to competitors' 1.2 trillion while outperforming them by 19.05 points in benchmark tests.
Revolutionizing Multimodal Understanding
The core innovation of OmniVinci lies in its ability to simultaneously process and interpret visual, audio, and text information. This breakthrough mimics human sensory integration, enabling machines to develop more comprehensive environmental understanding.
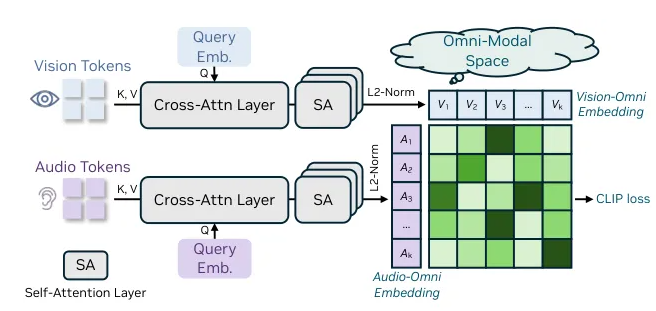
"OmniVinci represents a paradigm shift," explained Dr. Liang Zhao, lead researcher on the project. "Rather than brute-forcing performance through massive datasets, we've developed novel architectural approaches that maximize learning efficiency."
Architectural Breakthroughs
The model employs several groundbreaking technologies:
- OmniAlignNet: Specialized module aligning visual and audio data streams
- Temporal embedding grouping: Enhances sequential data processing
- Constrained rotational temporal embedding: Improves time-series comprehension
These components work synergistically within a unified latent space framework, allowing seamless information exchange between modalities before feeding into NVIDIA's large language model backbone.
Two-Stage Training Approach
The research team implemented an innovative training regimen:
- Modality-specific pre-training: Individual optimization of visual, audio, and text processing pathways
- Full-modal joint training: Integrated learning that reinforces cross-modal associations
This methodology yielded surprising efficiency gains while maintaining exceptional accuracy across all tested benchmarks.
Implications for Future AI Development
The open-sourcing of OmniVinci signals NVIDIA's commitment to advancing foundational AI research while providing practical tools for developers worldwide. Industry analysts predict this technology will accelerate progress in:
- Autonomous systems
- Accessibility technologies
- Content moderation solutions
- Advanced human-computer interfaces
The GitHub repository (github.com/NVlabs/OmniVinci) has already attracted significant attention from the research community.
Key Points:
🌟 19.05-point benchmark advantage over current top models
📊 Sixfold data efficiency (0.2T vs 1.2T tokens)
🔑 Innovative architecture enables superior multimodal integration
🌐 Open-source availability accelerates industry adoption




