Moonlight AI's Kiwi-do Model Stuns With Visual Physics Prowess
Moonlight AI Unveils Breakthrough Multimodal Model
In a development that's set tongues wagging across the AI community, Moonshot AI appears to have quietly introduced "Kiwi-do" - a sophisticated new model demonstrating exceptional visual reasoning capabilities. The emergence follows Moonshot's recent $3.5 billion Series C funding round.
Accidental Discovery Sparks Buzz
The model first surfaced unexpectedly on benchmarking platform LmArena, where an eagle-eyed researcher noticed its impressive performance metrics. When questioned about its origins, Kiwi-do identified itself as coming from "Moonshot AI" - fueling speculation this might be an early version of their anticipated K2-VL multimodal system.
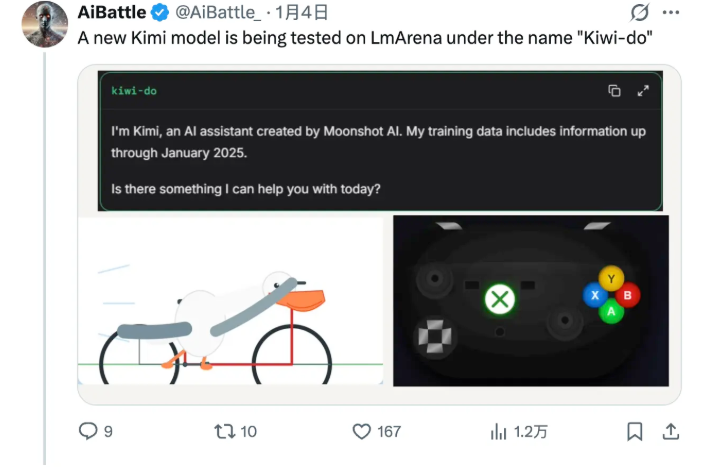
What makes Kiwi-do particularly intriguing is its training data cutoff of January 2025 - remarkably current by industry standards. But it's the model's performance on the demanding Visual Physics Comprehension Test (VPCT) that has researchers truly excited.
Pushing Multimodal Boundaries
"The VPCT results suggest something fundamentally different from existing models," explains Dr. Lin Wei, an AI researcher unaffiliated with Moonshot. "This isn't just incremental improvement - we're seeing qualitative leaps in how the system connects visual inputs with physical reasoning."
The implications could be significant for practical applications ranging from technical document analysis to real-time dashboard interpretation - areas where current systems often stumble.

Ahead of Schedule?
Moonshot had previously indicated plans to launch enhanced multimodal capabilities later this quarter, potentially branded as K2.1 or K2.5. Kiwi-do's sudden appearance raises questions about whether development is progressing faster than expected.
Comparative testing shows clear distinctions between Kiwi-do and Moonshot's existing K2-Thinking model, particularly in SVG rendering tasks. The differences appear substantial enough to confirm they're distinct systems.
What This Means for AI Development
The tech community is watching closely to see if Kiwi-do represents:
- An internal test version of the upcoming K2 series
- A specialized spin-off targeting visual reasoning
- Something entirely new in Moonshot's pipeline
One thing seems certain: if these early indicators hold, we may be looking at a significant step forward in making AI systems truly understand—not just process—the visual world around us.
Key Points:
- Unexpected debut: Kiwi-do model spotted performing exceptionally well on benchmarking platforms
- Visual physics standout: Demonstrates unusually strong performance on complex VPCT assessments
- Commercial potential: Could enhance real-world applications like document analysis and data visualization
- Development mystery: May represent accelerated progress toward Moonshot's planned K2-series release





