ByteDance, HK Universities Open-Source DreamOmni2 AI Image Editor
ByteDance and Hong Kong Universities Release Open-Source DreamOmni2 AI Image Editor
In a significant advancement for AI-powered image editing, ByteDance has partnered with researchers from The Chinese University of Hong Kong, Hong Kong University of Science and Technology, and The University of Hong Kong to open-source DreamOmni2. This innovative system represents a leap forward in multimodal AI understanding, particularly for processing abstract visual concepts.
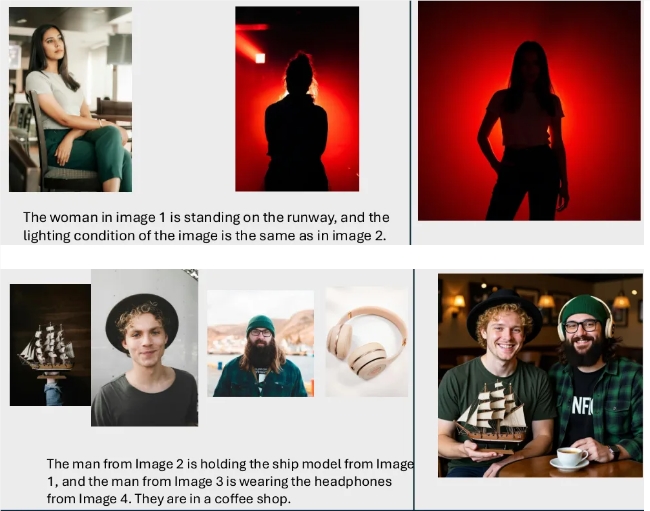
Breaking Through Abstract Concept Barriers
The newly released system addresses longstanding challenges in AI image processing, where previous models struggled with interpreting abstract instructions about style, material, and lighting. DreamOmni2 introduces groundbreaking capabilities:
- Simultaneous processing of text instructions and reference images
- Improved accuracy in maintaining image consistency during edits
- Natural interaction flow resembling human-to-human collaboration
"This isn't just another image generator," explains Dr. Li Wei, lead researcher from CUHK. "We've created an AI that truly comprehends artistic intent across multiple input modalities."
Three-Stage Training Process
The development team implemented an innovative training methodology:
- Extraction Model Training: Teaches AI to identify specific elements or abstract properties within images
- Multimodal Data Generation: Creates comprehensive training samples combining source images, instructions, reference images, and target outputs
- Dataset Expansion: Further refines the system through additional extraction and combination processes
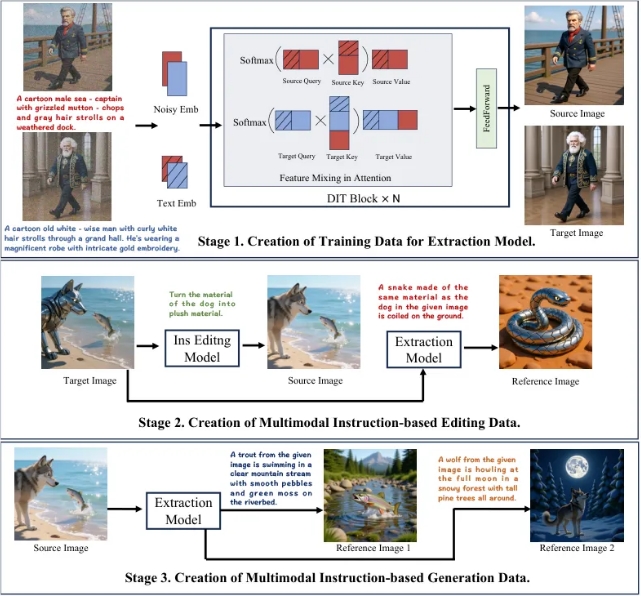
Technical Innovations
The system incorporates several novel technical approaches:
- Index Encoding Scheme: Precisely identifies multiple input images within complex workflows
- Position Encoding Offset: Maintains spatial relationships during processing
- Visual Language Model (VLM) Bridge: Effectively translates user instructions into actionable edits
"The VLM component was crucial," notes ByteDance engineer Zhang Tao. "It's what allows the system to understand when you say 'make it more impressionistic' while showing a Monet reference."
Performance Benchmarks
Independent testing shows DreamOmni2:
- Outperforms all comparable open-source models
- Approaches capabilities of top commercial solutions
- Demonstrates superior accuracy with complex instructions
- Minimizes unwanted artifacts common in other systems
The open-source release includes standardized evaluation metrics, providing researchers with consistent benchmarks for future development.
Industry Impact
The availability of this technology promises to:
- Democratize advanced AI image editing capabilities
- Accelerate research in multimodal AI systems
- Establish new standards for instruction-following accuracy "We're seeing the beginning of a new era in creative AI," remarks Stanford Professor Elena Rodriguez. "Systems like DreamOmni2 blur the line between tool and creative partner."
The complete DreamOmni2 framework is now available on GitHub under an open-source license.
Key Points:
- Breakthrough in multimodal AI understands both text and visual references
- Novel three-stage training process enables abstract concept comprehension
- Outperforms existing open-source solutions while approaching commercial quality
- Open-source release includes standardized evaluation benchmarks
- Potential to transform creative workflows across multiple industries





