Tencent Unveils Low-Cost AI Optimization Method
Tencent's Breakthrough in Cost-Efficient AI Optimization
Tencent AI Lab has developed Training-Free GRPO (Gradient-based Policy Optimization), a revolutionary approach to optimizing large language models without traditional parameter fine-tuning. This innovation significantly reduces computational costs while delivering comparable performance improvements.
How Training-Free GRPO Works
The technology converts experiential knowledge into token-level prior information, allowing models to improve without altering their core parameters. By maintaining an external experience knowledge base dynamically, the method enhances capabilities while preserving the main model's architecture.
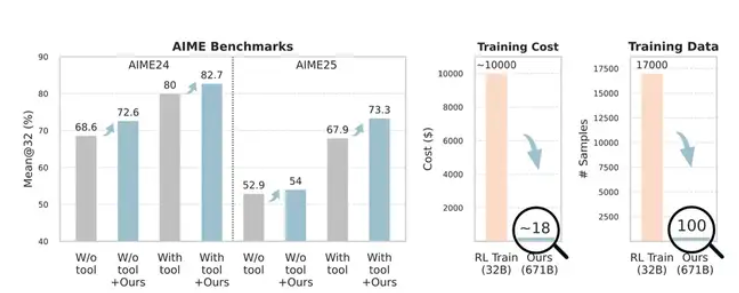
Performance Improvements
Tests on DeepSeek-V3.1-Terminus showed notable gains:
- Mathematical reasoning: Accuracy increased from 80% to 82.7% on AIME24 and from 67.9% to 73.3% on AIME25
- Web search tasks: Pass@1 metric improved from 63.2% to 67.8%
The method achieved these results using just 100 cross-domain training samples, whereas traditional approaches typically require thousands.
Cost Comparison
The financial implications are staggering:
- Traditional fine-tuning: ~70,000 RMB
- Training-Free GRPO: ~120 RMB
The savings come primarily from avoiding computationally intensive operations like gradient backpropagation and parameter updates.
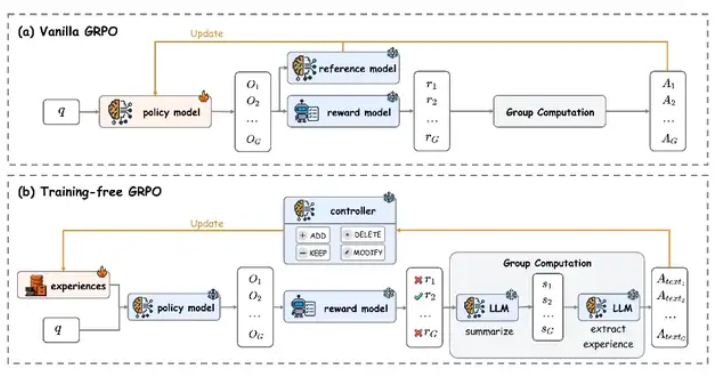
Implications for AI Development
This breakthrough could democratize access to advanced AI optimization:
- Enables smaller organizations with limited resources to enhance model performance
- Maintains model generalization across domains
- Opens new possibilities for efficient continuous learning systems
The research team acknowledges that further testing is needed across broader task categories beyond mathematical reasoning and information retrieval.
Paper Reference: Training-Free GRPO on arXiv
Key Points:
- Achieves similar results as traditional fine-tuning at <0.2% of the cost
- Works by updating external knowledge bases rather than model parameters
- Demonstrated effectiveness in mathematical and search tasks
- Particularly valuable for resource-constrained organizations



