Shanghai Researchers Boost AI Reflection Capabilities
Shanghai Team Advances AI Reasoning Capabilities
Researchers from Shanghai Jiao Tong University and the Shanghai Artificial Intelligence Laboratory have made significant progress in enhancing the reflective abilities of multimodal large models (MLLMs). Their innovative MM-HELIX project addresses a critical limitation in current AI systems - the inability to effectively backtrack and reconsider approaches when facing complex challenges.
The Reflection Challenge in AI
While MLLMs demonstrate impressive capabilities in solving complex problems, they often exhibit "rigid" behavior during reasoning processes. Unlike humans who can reflect on their approach after encountering obstacles, current models struggle with this metacognitive ability. This limitation becomes particularly evident when handling tasks requiring multiple solution attempts or adaptive strategies.
Building MM-HELIX: A Comprehensive Solution
The research team took a three-pronged approach:
- The Ultimate Exam Benchmark: Developed to evaluate reflective reasoning across 42 highly complex tasks spanning algorithms, graph theory, puzzles, and strategy games.
- MM-HELIX-100K Dataset: Contains 100,000 high-quality samples teaching models reflection through "step-by-step heuristic response generation" (SERG).
- Adaptive Hybrid Policy Optimization (AHPO): An intelligent tutoring algorithm that gradually shifts models from expert guidance to independent exploration.
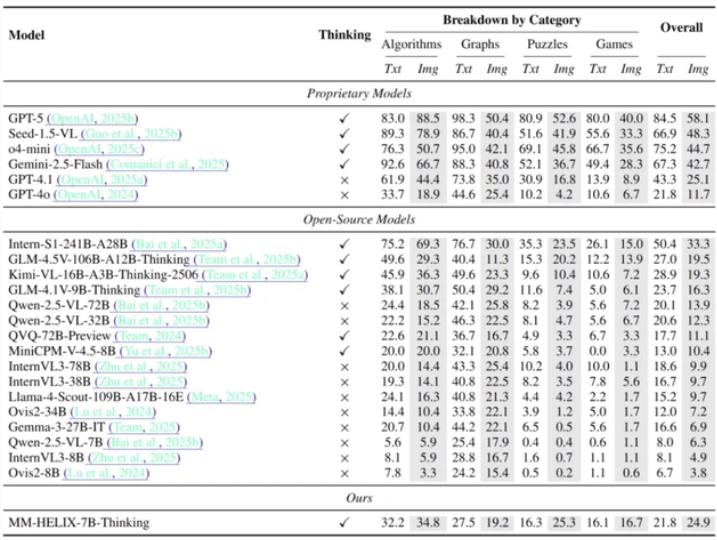
The benchmark tests revealed even state-of-the-art models performed poorly on reflective tasks, particularly under multimodal input conditions.
Measurable Improvements
The implementation showed promising results:
- The SERG process reduced problem-solving time significantly while minimizing redundant thinking
- Models equipped with MM-HELIX demonstrated stronger generalization capabilities
- The Qwen2.5-VL-7B model achieved an 18.6% accuracy increase on benchmark tests
Key Points:
- Current MLLMs lack effective reflection capabilities for complex reasoning tasks
- MM-HELIX provides tools for evaluation (benchmark), training (dataset), and optimization (algorithm)
- The system mimics human learning progression from guided to independent problem-solving
- Demonstrated performance improvements validate the approach's effectiveness


