LLaVA-OneVision-1.5 Outperforms Qwen2.5-VL in Benchmarks
LLaVA-OneVision-1.5 Sets New Standard for Open-Source Multimodal Models
The AI landscape has welcomed LLaVA-OneVision-1.5, a fully open-source multimodal model that represents a significant leap forward in visual-language understanding. Developed over two years as part of the LLaVA (Large Language and Vision Assistant) series, this latest iteration demonstrates superior performance compared to established models like Qwen2.5-VL.
Innovative Three-Stage Training Framework
The model's development follows a meticulously designed three-stage training process:
- Language-image alignment pre-training: Converts visual features into linguistic word embeddings
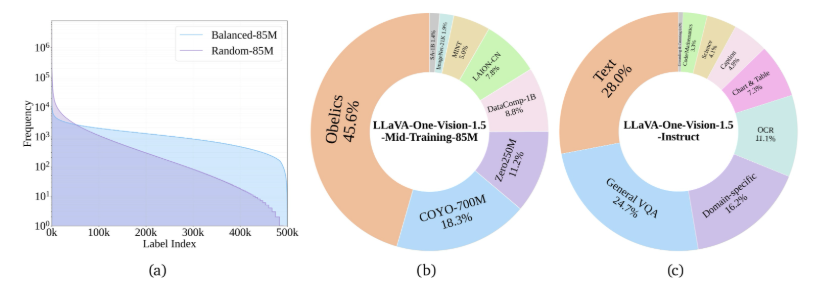
- High-quality knowledge learning: Trains on 85 million samples to enhance visual and knowledge capabilities
- Visual instruction fine-tuning: Specialized training for complex visual instructions
Breakthrough Efficiency Gains
The development team implemented several innovations to optimize training:
- Offline parallel data packaging achieving an 11:1 compression ratio
- Complete training cycle accomplished in just 3.7 days
- Utilizes RICE-ViT as visual encoder for superior document text processing
The model's regional perception capabilities make it particularly effective for tasks requiring detailed visual understanding.
Benchmark Dominance
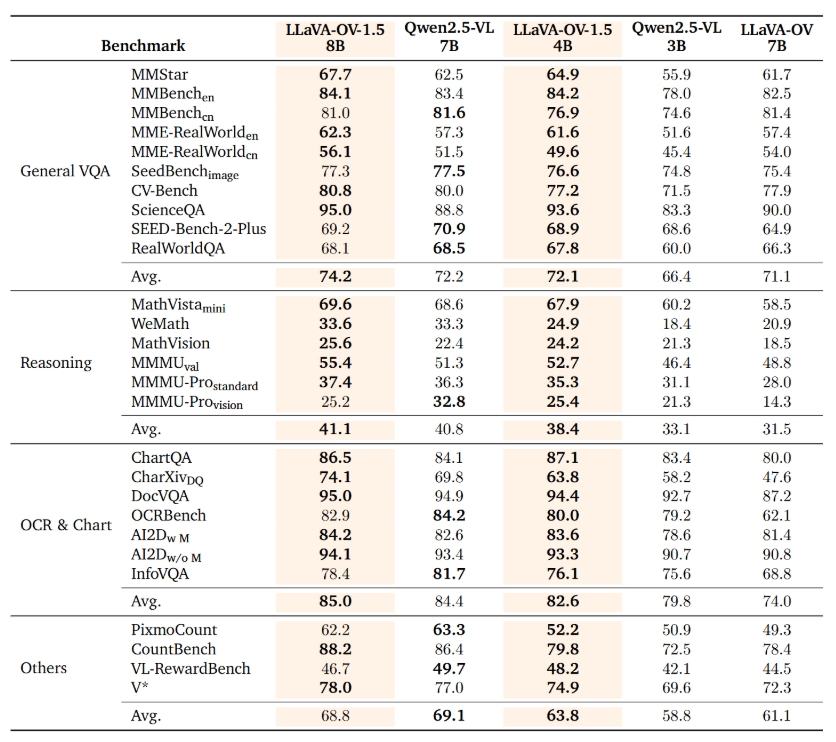
The 8-billion-parameter version demonstrates remarkable performance:
- Outperforms Qwen2.5-VL across 27 different benchmarks
- Employs "concept-balanced" sampling strategy for consistent task performance
- Processes diverse input types including images, videos, and documents
The project maintains full transparency with resources available on GitHub and Hugging Face.
Key Points:
✅ Fully open-source multimodal architecture surpassing proprietary alternatives
✅ Revolutionary three-phase training methodology
✅ Unprecedented efficiency gains through innovative data handling
✅ Benchmark-proven superiority over competing models





