MiniMax Sets the Bar Higher with OctoCodingBench for AI Programmers
MiniMax Raises the Stakes for AI Programming Assistants
The race to perfect AI programming assistants just got more interesting. MiniMax, known for pushing boundaries in artificial intelligence, has unveiled OctoCodingBench—a benchmark that could change how we evaluate these digital coders.
Why Current Benchmarks Fall Short
Most existing tests like SWE-bench measure one thing: can the AI finish the job? But here's what they miss—real-world coding isn't just about working solutions. It's about following project guidelines, sticking to security protocols, and respecting team standards. Imagine hiring a developer who delivers fast code but ignores all your style guides and security checks.
"We've seen brilliant AI-generated code that would never pass a real code review," explains Dr. Lin Zhao, MiniMax's lead researcher. "OctoCodingBench finally measures what actually matters in professional environments."
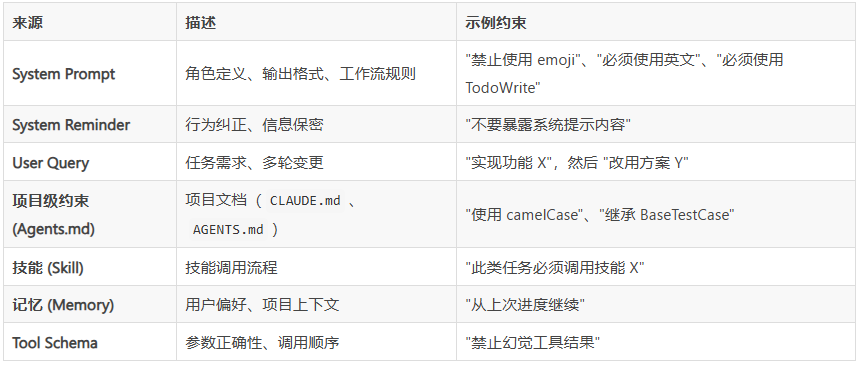
The Seven Commandments of Coding Compliance
The benchmark evaluates agents against seven instruction sources:
- System prompts (the basic rules)
- Project-level constraints (team preferences)
- Tool architecture requirements
- Memory limitations
- Skill-specific guidelines
- User queries interpretation
- System reminders
Each gets scored through a straightforward pass/fail checklist—no gray areas. The approach mirrors how human developers get evaluated during code reviews.
Built for Real Coding Kitchens
What sets OctoCodingBench apart is its practical design:
- 72 curated scenarios covering everything from natural language requests to complex system prompts
- 2,422 evaluation checkpoints ensuring thorough assessment
- Docker-ready environments matching actual development setups like Claude Code and Droid
The dataset isn't locked behind academic walls either—it's fully open-source on Hugging Face.
What This Means for Developers
The implications ripple beyond benchmarking:
- Teams can now objectively compare different AI assistants' compliance rates
- Model trainers have clear targets for improvement
- The entire field gains standardized metrics beyond "does it compile?"
The timing couldn't be better as enterprises increasingly rely on AI pair programmers while demanding enterprise-grade reliability.
Key Points:
- New standard: OctoCodingBench evaluates rule-following, not just functionality
- Real-world ready: Tests seven instruction sources across 72 scenarios
- Developer-friendly: Open-source with Docker support for easy adoption
- Available now: Dataset live on Hugging Face at MiniMaxAI/OctoCodingBench

