Google AI Introduces Stax for Custom LLM Evaluation
Google AI Launches Stax for Custom LLM Evaluation
Google AI has unveiled Stax, an experimental evaluation tool designed to help developers assess large language models (LLMs) with greater precision. Unlike traditional software testing, LLMs are probabilistic systems that may produce varied responses to identical prompts, complicating consistent evaluation. Stax provides a structured framework to address this challenge.
Addressing the Limitations of Traditional Benchmarks
While leaderboards and general benchmarks track high-level model progress, they often fail to reflect domain-specific requirements. For instance, a model excelling in open-domain reasoning might underperform in legal text analysis or compliance summaries. Stax allows developers to define custom evaluation processes tailored to their use cases.
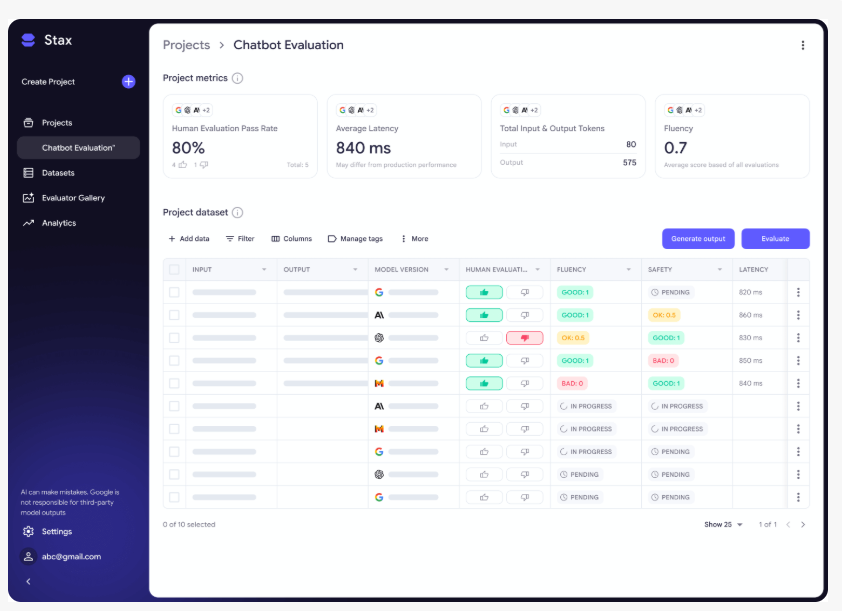
Key Features of Stax
Quick Comparison
The Quick Comparison feature enables side-by-side testing of multiple prompts across different models. This reduces trial-and-error time by clarifying how prompt design or model selection impacts outputs.
Projects and Datasets
For larger-scale testing, developers can create structured test sets and apply consistent evaluation criteria across multiple samples. This supports reproducibility and realistic condition assessments.
Auto Evaluator
The core of Stax is its Auto Evaluator, which allows developers to build custom evaluators or use pre-built options. Built-in evaluators cover:
- Fluency: Grammatical correctness and readability.
- Factuality: Consistency with reference material.
- Safety: Avoidance of harmful or inappropriate content.
Analytics Dashboard for Deeper Insights
Stax’s analytics dashboard simplifies result interpretation by displaying:
- Performance trends.
- Output comparisons across evaluators.
- Model performance on identical datasets.
This transition from ad-hoc testing to structured evaluation helps teams better understand model behavior in production environments.
Key Points
- 🚀 Stax is Google AI’s experimental tool for custom LLM evaluation.
- 🔍 Features like Quick Comparison and Projects and Datasets streamline testing.
- 📊 Supports both custom and pre-built evaluators for domain-specific needs.



