Gemini-3-Pro Leads Multimodal AI Race as Chinese Models Gain Ground
Multimodal AI Showdown: Who's Winning the Vision-Language Race?
The battle for supremacy in multimodal artificial intelligence has taken an interesting turn with December 2025's SuperCLUE-VLM rankings. These evaluations measure how well AI systems understand and reason about visual information - a crucial capability as machines increasingly interact with our image-rich digital world.
The Clear Frontrunner
Google's Gemini-3-Pro continues its dominance with an overall score of 83.64 points, leaving competitors in the dust. Its performance is particularly strong in basic image understanding (89.01 points), though even this leader shows room for improvement in visual reasoning (82.82) and application tasks (79.09).
"What makes Gemini stand out isn't just raw scores," explains Dr. Lin Zhao, an AI researcher at Tsinghua University. "It's their consistent performance across all test categories while others excel in specific areas but falter elsewhere."
China's Rising Stars
The real story might be China's rapid advancement:
- SenseTime's SenseNova V6.5Pro claims second place (75.35 points)
- ByteDance's Doubao impresses with third place (73.15 points)
- Alibaba's Qwen3-VL makes history as first open-source model to cross 70 points
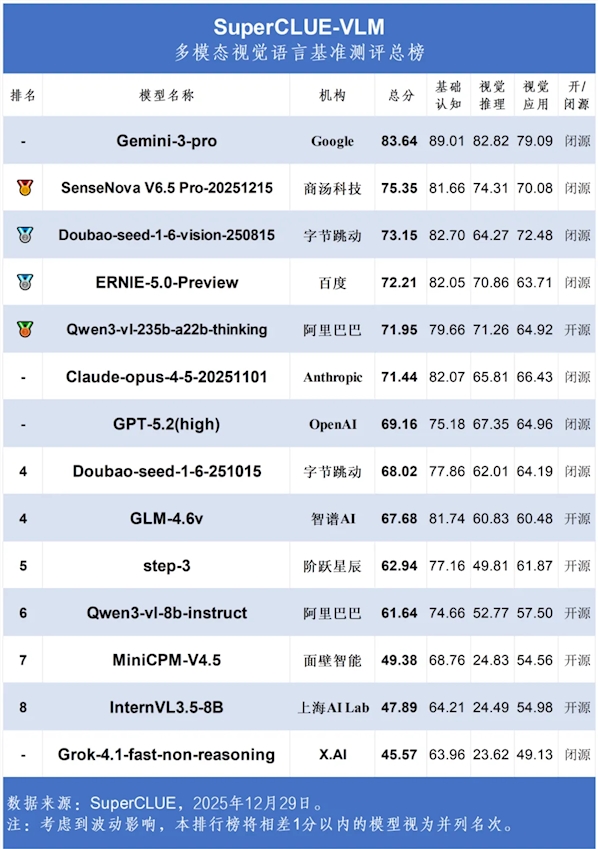
These results suggest Chinese tech firms are prioritizing capabilities particularly useful domestically - think analyzing social media images or short video content.
Surprises and Stumbles
The rankings held some shocks:
OpenAI's much-hyped GPT-5.2 landed a disappointing 69.16 score despite its high configuration, raising questions about its multimodal development priorities.
Meanwhile, Anthropic's Claude-opus-4-5 delivered steady performance (71.44 points), maintaining its reputation for strong language understanding capabilities.
What These Scores Really Mean
The SuperCLUE-VLM tests evaluate three crucial skills:
- Basic Cognition: Can the AI identify objects and text?
- Visual Reasoning: Does it understand relationships and context?
- Application: Can it perform practical tasks like answering questions about images?
The results reveal where progress is happening fastest - and where challenges remain:
"We're seeing incredible advances in basic recognition," notes Dr. Zhao, "but higher-order reasoning still separates the best from the rest."
The strong showing by open-source Qwen3-VL could democratize access to powerful multimodal tools, while commercial models like Doubao demonstrate how specialized training pays off for specific use cases.
Key Points:
- Google maintains leadership but Chinese models are closing gaps rapidly
- Open-source options now compete with proprietary systems
- Visual reasoning remains toughest challenge across all platforms
- Performance varies dramatically by application - no one-size-fits-all solution yet



