DeepSeek's New AI Models Take on Tech Giants
DeepSeek Levels Up With Dual AI Release
The AI research community just got exciting new tools to play with. DeepSeek has launched version 3.2 of its flagship models, bringing serious competition to closed-source alternatives from big tech companies.
Two Models, Double the Impact
The company introduced two variants:
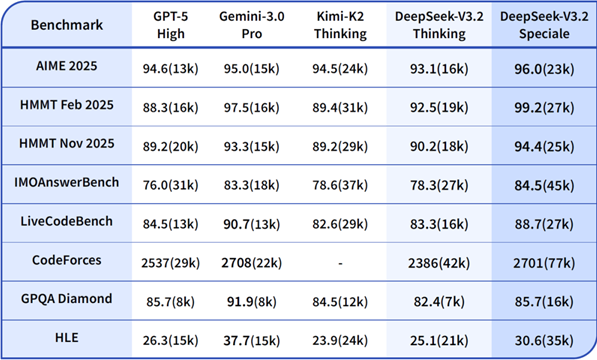
- V3.2 Standard Edition: Performs neck-and-neck with OpenAI's GPT-5 when handling documents up to 128,000 words
- V3.2-Speciale: Matches Google's Gemini3Pro on academic benchmarks while producing more detailed answers
Technical Breakthroughs Under the Hood
The secret sauce? A clever innovation called Directory-Style Attention (DSA). Traditional AI models struggle with long documents because processing time grows exponentially with length. DSA changes this dramatically:
- Makes processing time grow linearly instead of exponentially
- Uses 40% less memory
- Runs inferences 2.2 times faster
The result? These are the first open-source models capable of handling million-token documents on a single graphics card.
Smarter Thinking Through Better Training
The DeepSeek team didn't cut corners on training either:
- Dedicated over 10% of their computing power specifically to reinforcement learning
- Used group-based reinforcement learning (GRPO) combined with majority voting
- Removed artificial limits that discouraged lengthy reasoning chains
The payoff shows in testing - Speciale produces answers that are not only longer (32% more tokens than Gemini3Pro) but also more accurate (4.8 percentage points higher).
Open Source Commitment Continues
Both models are available now on GitHub and Hugging Face under the business-friendly Apache 2.0 license. DeepSeek promises more openness ahead: "We're planning to release our DSA kernel and RL training framework next," a company spokesperson said.
The move continues DeepSeek's strategy of turning proprietary advantages into community assets - an approach that could reshape the competitive landscape by 2026 if they maintain this pace.
Key Points:
- Performance Parity: Matches GPT-5/Gemini3Pro capabilities in respective domains
- Technical Innovation: DSA enables efficient million-token processing
- Training Investment: Significant computing resources devoted to RL optimization
- Open Philosophy: Full weights available commercially under Apache 2.0 license

